Creating a reference data architecture…
I wanted to share my thought process while creating a reference data architecture. Hopefully it will help you define yours our help me improve mine by providing feedback.
I think reference architectures serve as a goal to strive for, rather than simply reflecting the current state. In my opinion reference architectures should be vendor-agnostic, but highlight important/mandatory tech functionality. A reference architecture might (and should) include components not currently in use, in order to have a broader perspective from our current position.
My reference architecture is based upon hands-on experience accumulated over many years working with a diverse range of companies and technology. I combine my practical experience with hours and hours of reading publications from our community. This reference architecture also forms the basis of my work with Simplitics, which I have begun to describe on Medium, starting with my post...
Why do I feel the need to publish this post describing my reference data architecture?
Well, It is a way for me to describe my beliefs and how Simplitics is composed. And I haven’t really found many similar (public) writings, that focus on data architecture as a general architecture for all data consuming disciplines, highlighting requirements and capabilities without vendor logos…
Furthermore, it is really really hard to start from a vendor offering and build from that, so this could indeed help.

For high resolution follow any of the links below.
MAD 2023 — Version 1.0 (mattturck.com)
The 2023 MAD (Machine Learning, Artificial Intelligence & Data) Landscape — Matt Turck
A simple glance at a data tech map will guide us to a few conclusions.
- How can anyone assess and select the right tools for the job? Without spending alot of time evaluating! How much time would it actually take to assess and evaluate all needed aspects of each and every product?
- We can’t settle with a few tools for the task, which leads to a steep learning curve for the team...
- We need to build something that can change and adopt/replace tools down the path since everything is evolving and we might not have the best tool for the task, yet…
So can we start from what is shared by the community instead?
I decided to spend several hours on browsing HOW other people have defined and described their data architecture? I copied a bunch of diagram into a slideshow below.
We can witness a wide selection of detailed and general diagrams, followed by vendor specific diagrams. Let me summarize that most diagrams include a lot of tech and very little architectural “functionality”. Enterprise architecture diagrams on the other hand, show us the opposite. Professionals trying to describe their actual environments end up in the middle, with a blend of tech and “functionality”.
The bottom line is that most architectures described are based on the available tech stacks and not on the required capabilities.
With this in mind, let me share my reference architecture.
I strive to build a data architecture that is adaptable and sustainable, which can accommodate all your data needs, being ML/AI, analytics or data apps. A data architecture consists of many modules which must interact and “feed” of each other, much like any eco-system.
So, setup a data architecture that is built to adapt. Any code, module and/or component should be portable to another platform, tech stack and/or service.
Make sure we spend as little time as possible on repeatable tasks and more and more time on data modelling and definitions.
So after listing and defining my requirements and capabilities, which you can read about in detail further down in this text, I created my vendor agnostic reference architecture, which looks like this…
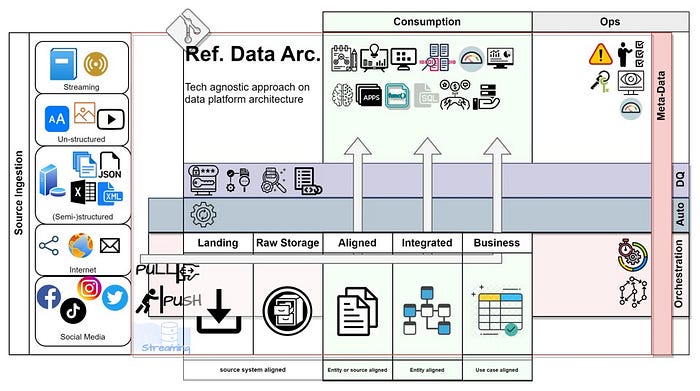
We now have a diagram full of disciplines and capabilities, drawn as a multilayered approach. Use your documented requirements and detail each discipline with those that matter, both as requirement but also as answers to your requirements…
Ok, so how do we view this picture?
From left to right, through the middle, and up. Components at a higher position are more important than those at a lower position. Yet all components are valid and important for a well equipped “eco-system” (What each icon represents is described further down in this post).
At the far left we have sources of various type, all with specific characteristic to consider. These are usually; internal legacy systems, ERP’s, SAAS, custom built, micro services, databases, logs, devices and social media etc..
In order to get data across through to the middle we need some form of source ingestion in the shape of pull, push and streaming. Data is received and stored in a landing area and later organized into a raw “untampered” storage for the sake of auditing and reprocessing.
From there, we align data into selected formats and context and make it accessible. We further integrate data into entities and extended context making it even more accessible. Later to expose data into the format required by our specific business use-case for simple and accurate access. It is not always required for all data to “travels“ through all five layers of enrichment. Consumption can happen from any of the later three layers (aligned, integrated and business ) depending on our actual needs.
From source ingestion to business alignment, we create programs and/or data flows which need orchestration and scheduling. We emphasis on automation of our internal processes, hence it stretches over all layers and is of higher importance in our diagram.
Our second highest priority is data quality and it is a discipline with practice throughout all our layers. Our highest priority on the other hand is our end usage; our consumption and operations. We should focus on our end usage and let it drive everything else. Our internal data operations (or data governance or data ops) is as important as any other user or application. This leads to metadata as being a crucial component which must capture data about all schemas, models, definition, data, processes , events and usage.
If you are interested in what each capability each icon represents, please read on, otherwise feel free to stop here… Maybe you are not found of “icon based” diagrams, so if you prefer, here is a textual alternative…
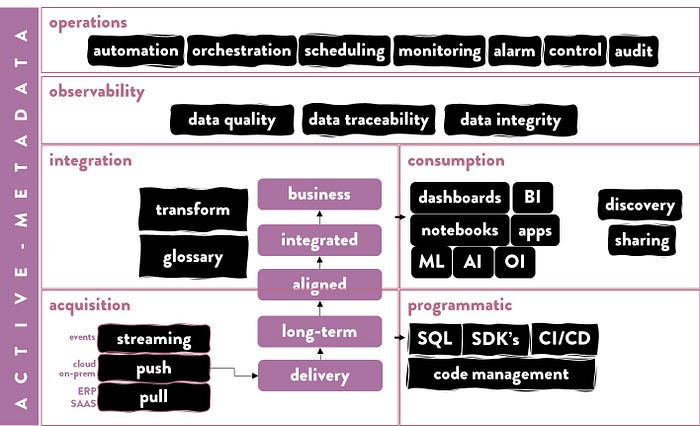
This is the same architecture yet without icons and drawn a bit differently. It consists of the exact same layers and capabilities as the previous diagram. The following section relates to my process describes the capabilities and requirements I have used as the basis for my reference architecture…
Step 1: Gather, list and describe you’re desired capabilities.
These should include specific capabilities for known, driving use cases and more general capabilities for future unknown use cases. I usually categorize these capabilities into groups and keep the description at a high level, except for the driving initiatives. Let me illustrate using the following extensive list.
Data acquisition
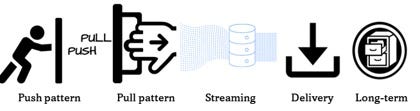
- We need a push data pattern for allowing systems to send data.
- We need a pull data pattern for getting data out of systems.
- We need a streaming data pattern to allow for instant and continual access to data.
- We need a placeholder for arriving data, a delivery zone or upload area.
- We need a long-term archive for traceability, reprocessing and audit.
Data Observability
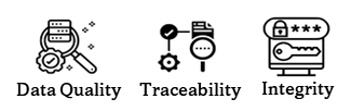
- We need to be able to observe and test our data quality against; completeness, consistency, validity and freshness.
- We need to gather and display the trace of all data points/products. The origin, how it was generated, how it has been processed and transformed over time and for which users/applications it serves.
- We need to ensure that data is not misused or misrepresented and only available to those whom it may concern.
Data Integration
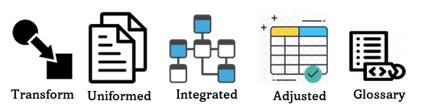
- We need to have a transform capability in order to achieve new states and forms of data as stated below.
- We need to uniform our data so that access is simplified and possible.
- We need to integrate data in order to consolidate data, provide broader perspectives, create similarity and define concepts and definitions that can be shared.
- We need to adjust our data into a form suitable for its application.
- We need to define a glossary with definitions, terminology and concepts
Programmatic access
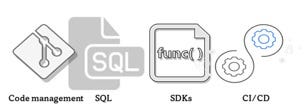
- We need to enable a corporate code management standard, such as git or similar
- The most commonly used language for data processing and manipulation by people and tech is by far SQL. So for now enabling SQL access to your data is crucial.
- We need to open up our data access for various tools and avoid tech lock in by either creating SDK’s for our data or providing templates for various programming languages.
- It is important to incorporate a CI/CD process for any code which needs to be saved, tracked and moved between different technical setups in order to improve code quality, sharing and development pace.
Day to day operations

- We need to automate our processes as much as possible.
- We need to be able to orchestrate our data flows/pipelines with sequencing, fan-in and fan-out abilities.
- We need to schedule certain data flows and tasks.
- We need to be able to monitor our tech landscape, our data pipelines, our resource consumption, our financial spend and our data quality.
- We need to be able to create alarms on critical events.
- We need to setup a series of controls to ensure that our data landscape keeps on going and maintains high quality services for our end users and consuming applications.
- We need to be able to audit how data has been accessed, modified by whom and when.
Data consumption

- We need a operational intelligence capability, in order to turn data into actionable insights that help our organization optimize operations and improve the bottom line.
- We need BI and reporting in order to present data in ways to describe and report how our business is going and to help our organization make better decisions, improve operations and achieve a competitive advantage.
- We need dashboard abilities so that we make data relevant and present the right information to the right stakeholders.
- We need some kind of notebook capability so that our more advanced users can elaborate, develop, process, present and share data and programs among each other.
- We need a set of tools and processes to run AI and ML initiatives on our data. Model training, evaluation, validation, audit and publishing, and maybe some specific commercials libraries
- We need to open up our data landscape for data applications. Applications that consume data and produce “new” enriched data for another purpose.
- We need to give our users a way to discover data using a search approach.
- We need to allow our users to share data and code between each other.
This is most likely the area where you would detail your capabilities a bit. For specific needs please detail those, otherwise settle for my high-level definitions. For instance you might need NLP capabilities for your use cases and maybe some infrastructure for parallel processing and some kind of registry and orchestration for your ML features.
Step 2: understand your requirements
Many data architectural requirements are quite general but very important to take into consideration.
I recently wrote a post about the underlying overall requirements that should influence the entire architecture and manifested in all components and functionality. I find these very important!
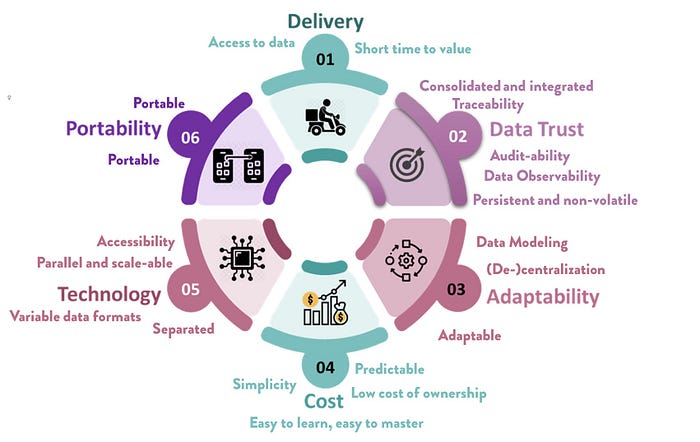
Of course the list of requirements written in the linked post is not sufficient, you will have other more practical requirements as well, such as latency, look and feel, money constraints, staff skill set, performance, distribution, laws and policies and more.
Step 3: Summarize and define
Summarize all requirements and capabilities and define your reference architecture. We have a set of capabilities that needs to be put into context and organised. We have a set of overall requirements to consider. Our requirements help us putting our capabilities into context, limit or enable each other. Most likely you’ll end up creating a multilayered architecture similar to mine.
My reference architecture can be used both in a classical centralized implementation #datawarehouse or as a modern decentralized implementation #datamesh.

Our classical centralized data warehouse works perfectly in this architecture. For instance we could gather data into cloud buckets, configure a cloud data warehouse to access the buckets and automatically load data. We work hard on defining a centralized data model and on creating functionality for loading automation and data observability. We create use-case based datasets in star-schemas, tabular and multi-dimensional cubes. We configure consumption tools for the appropriate dataset and centralize our security, integrity and access functionality. Everything is accounted for by a central cross-functional team. Integration and reuse-ability is in focus in these setups.
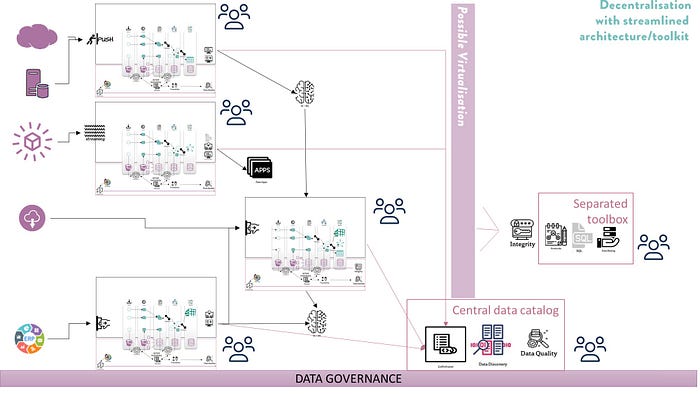
In this architecture we want to achieve decentralization, in order for teams to improve productivity and keep complexity within a domain boundaries. Yet, we still want implementations to follow the same guidelines, frameworks and methodologies across implementations. In these scenarios we are highly benefited from carefully planned architecture and policies. The key for success is; automation of processes, structure, flows and metadata. With those things in place we can easily enable a central data catalog and enable users to find and access their required data, perhaps using a virtualization tool. In my reference diagram above, we have the same architectural layout (and components) but in several instances. We centralize data access, publication and discovery.
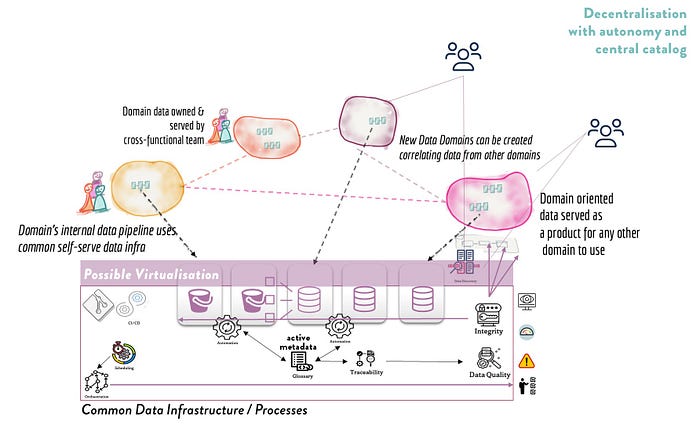
Decentralization with autonomous teams can also benefit from carefully planned architecture and policies. This time we manifest the architecture as a common data infrastructure as a service with automated processes for data publication, observability, integrity, discovery and access. Each domain will be able to handle their workload independently and using whatever in order to solve their need. However, if a domain wants to publish a data set or product, they must do so using our common data infrastucture service. So basically our common data reference architecture will only serve data meant for sharing, which come to think of it is ideal for great data discovery services…
Each and every variation of my reference architecture, can and should be be instantiated with great technology. The following step can guide you into your selection.
Step 4: Match with technical products.
So even if I said it to be tech agnostic, this is when we would try to map each capability icon against some tech. For instance.
- We pull with…
- We push using …
- For streaming data we use …
- We write and organize data into buckets at ….
- We align data into entities and publish them as … in …
- Integrate data into …. on ….
- Create … and publish them in ….
- Orchestrate flows/programs using ….
- We use …. as our scheduling tool
- For data validation we use …
- All data quality controls is created and monitored using …
- We record our data lineage in …
- Let’s store our definitions and glossary in …
- We store and publish metadata using …
- We monitor our system with ….
- We create alarms and warnings using …
- For resource and consumption planning we use …
- In order to run and monitor our operations we use …
- Our preferred notebook is …
- We use … for SQL access
- We use … for programmatic access
- For data discovery we use …
- We create dashboards using …
- We build and publish reports with …
- We integrate data into … using …
- We orchestrate our model training with …
- We publish our models in …
- We share data with …
- We integrate MA using …
- Our tool and data access is controlled by …
So 30 steps later we have a bunch of tech and their responsibilities/purpose. We can now start to connect and build our fine data landscape!
Good luck!
And don’t forget that I want to learn and improve this reference architecture, so drop me a comment or DM with thoughts, ideas and improvements.
My next couple of post will describe some of our actual implementations and how we glued it all together in the real and practical world :)
